Analytics can be worthless, counterproductive and even harmful when based on data that isn’t high quality. Garbage in, garbage out, as they say. So when Salesforce Analytics Cloud hit the market, vendors rushed to announce plugins that would load high-quality data into the solution.
The painful truth is that without high-quality data, it doesn’t matter how fast or sophisticated the analytics capability is. You simply won’t be able to turn all that data managed by IT into effective business execution.
The impact of bad data
Let’s look at a few common scenarios. These are based on real experiences, although I’ve left out the company names to protect the guilty.
- A company operating in the southeast region of the U.S. knew that the state of Georgia was its best market. With a new product coming out, it invested heavily in a targeted direct mail campaign, and only after the fact discovered that three-quarters of the postal addresses were bad. The campaign failed miserably.
- A cable company adjusted its service offering and bought a number of mailing lists to saturate the potential market. But because the company had no way to de-dupe the list, it ended up sending multiple pieces to the same person (Mike Stone, Michael Stone, Mike E. Stone, Michael E. Stone, M. Stone, etc.). This resulted in a significant waste of resources and angered a lot of existing and potential customers.
- An insurance company serving a specific region of the U.S. planned an email campaign but realized it had more names in its customer database than the number of adults living in the region! Upon investigating, it found that because it had no de-duping capability, no names were ever deleted from the list even though new names were constantly added. The company had no idea how stale the data was.
- A retailer invested heavily in collecting transaction data following a new product introduction. But the data in the transaction system did not sync with the data in the ordering system, so replenishment levels were nowhere near what they needed to be, and a huge opportunity was lost.
If you don’t know how dirty your data is, you don’t know what opportunities you’re missing. To put some numbers behind the potential harm of bad data, let’s look at a hypothetical direct mail marketing campaign. Imagine you spend $20,000 per month on a campaign to a highly targeted set of 100,000 customers in a specific market. Assume the annual cost of this program would be $240,000 (excluding employee and other operational costs). Based on previous experience, you know that each conversion from the campaign will result in a $100 gain in revenue, and you can count on about a 5 percent success rate, generating revenue of $500,000. After subtracting the $240,000 annual cost, the total annual profit for the program would equal $260,000.
But if your data quality is poor and your error rate is 50 percent (a not uncommon issue for enterprise sales and marketing departments due to duplicates, incorrect addresses, outdated lists, and so forth), the revenue would be cut in half to only $250,000, slashing the total annual profit for the program to just $10,000. If you include operational costs, you are likely losing money on the program.
To make matters worse, the pace of business is constantly accelerating, and organizations, along with their customers and partners, increasingly expect access to real-time and near real-time data. But let’s face it, it makes no sense -- and would be potentially disastrous-- simply to deliver bad data faster!
Ensuring high-quality data
To ensure sales and marketing teams always have access to high-quality data, organizations need to develop data management capabilities to ensure their data has been:
- De-duplicated -- Duplicate data within each system is deleted. This will, for example, eliminate multiple pieces of sales campaign mail going to the same person.
- Cleansed -- Inaccurate, incomplete, irrelevant, and corrupted records are identified and corrected. This can ensure that a mail campaign is actually targeted to real people at real addresses.
- Synchronized -- Data existing in multiple systems is made consistent. This can eliminate the disconnect between transaction and ordering systems, ensuring the appropriate level of replenishment.
- Enriched -- Raw data is enhanced and refined by linking with trusted, authoritative, industry-standard reference data repositories. The raw data in many systems may be incomplete and full of errors. Enriching data ensures that your data is complete and accurate.
- Refreshed -- Data is constantly kept up to date. A mailing list that was complete and accurate a year ago may be nearly worthless today. Data must be refreshed constantly in order to optimize any activity based on it.
Providing these capabilities is the role of master data management (MDM), a proven technology that until recently has been far too expensive for all but the largest companies to afford because it required the deployment of multiple systems from multiple vendors. Mid-market companies simply don’t have the time, budget or resources to purchase, deploy and manage multiple new systems.
Now, however, vendors have begun offering single platforms that include all of the essential MDM capabilities. Even better, some vendors offer their solution as a cloud-based service, eliminating the upfront costs as well as dramatically reducing the time and complexity of deploying the solution and managing the environment. MDM solutions can also feed solutions for complex event processing (CEP) and real-time analytics to ensure the deepest and most accurate insight at the speed of today’s businesses.
Every organization today depends on data to understand its customers and employees, design new products, reach target markets, and plan for the future. Accurate, complete, and up-to-date information is essential if you want to optimize your decision making, avoid constantly playing catch-up and maintain your competitive advantage.
Photo credit: Andrey_Popov / Shutterstock
![michaelm_hs_web230[1]](http://betanews.com/wp-content/uploads/2015/02/michaelm_hs_web2301-150x150.jpg) Michael Morton is the CTO of Dell Boomi, where he is responsible for product innovation. Michael joined Dell Boomi in 2013 after an impressive and successful career with IBM, where he became and IBM Master Inventor and worked directly with Fortune 100 Companies. He has been innovating and producing a wide-range of enterprise IT solutions for over 20 years. This includes being a founding developer of IBM WebSphere Application Server, as well as providing architecture leadership on the IBM InfoSphere data integration and IBM Tivoli systems management family of products. Michael’s broad experience coupled with his deep understanding of the complexities and challenges enterprise customers face when modernizing and attempting to remain competitive in the their industry rounds out his superb qualifications for the Chief Technology Officer position.
Michael Morton is the CTO of Dell Boomi, where he is responsible for product innovation. Michael joined Dell Boomi in 2013 after an impressive and successful career with IBM, where he became and IBM Master Inventor and worked directly with Fortune 100 Companies. He has been innovating and producing a wide-range of enterprise IT solutions for over 20 years. This includes being a founding developer of IBM WebSphere Application Server, as well as providing architecture leadership on the IBM InfoSphere data integration and IBM Tivoli systems management family of products. Michael’s broad experience coupled with his deep understanding of the complexities and challenges enterprise customers face when modernizing and attempting to remain competitive in the their industry rounds out his superb qualifications for the Chief Technology Officer position.









 Mike Tinney is a former video game company executive and the founder and CEO of
Mike Tinney is a former video game company executive and the founder and CEO of 



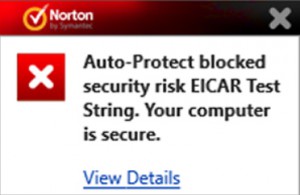 Your antivirus software claims to be working all the time, monitoring every file you access for any potential threats -- but is this really how it is?
Your antivirus software claims to be working all the time, monitoring every file you access for any potential threats -- but is this really how it is?