
Backup is often at the bottom of the list for IT teams -- an afterthought even -- but having an effective backup and disaster recovery plan in place means considering backup as an important piece of the IT strategy. Over the past two decades, IT departments have hosted dedicated physical servers per application, but as companies move to virtual environments, backup approaches must evolve too.
For most IT departments, the rotation for physical servers is: do a full backup of email and databases Monday -- Thursday; move to disk only the changed unstructured data files (incrementals) on Monday- Thursday; and then on Friday do a full backup of all data in the environment.
In some cases, IT departments perform changed-block backups, but the vast majority is a full file incremental during the week with a full backup on Friday. In the physical server world, you back up the data only. In some cases, you may do a complete image-based backup for bare metal restores but the vast majority of backup is data only.
For more than 20 years, IT departments have only had to worry about one thing when backing up their systems: data. As we move into an increasingly VM-dominated data center, there are many factors that need to be considered.
The move to a virtual environment and what it means: IT data centers are rapidly moving to a virtualized server world using VMWare, Hyper-V, and other hypervisors. While virtual servers still use direct attached storage, network attached storage, or storage area network storage, the backup application no longer backs up just the data -- now it backs up the entire virtual machine (VM).
This includes the guest operating system, the application, all associated system files, and the data. When you're backing up more than just data and preparing it for a recovery point at a later time in the event of a disaster, the way you think about backup needs to change too.
In the past, if a primary server failed for any reason, you would obtain a new server, load the server software or copy an image onto the server, and then restore the most recent data backups to ensure that the most up-to-date data is on the system. In the virtual world, VM backups are typically written to disk. Since the VM is sitting on backup disk, you can simply boot it from the backup system.
If the primary systems fail, you can boot a VM off the backup system and users can continue to work directly off the backup system. Once the hypervisor is used to make the primary systems operational, the user activity is transparently moved back to the primary systems through a VM instant recovery, allowing your recovery time to be minutes versus hours.
If a third-party auditor is auditing your business continuity, you can boot a VM of the backup system in order to demonstrate that you have a working copy of the entire VM, including data. In the past, it was almost impossible to show an auditor that you could recover from a failure. In the VM world, you can simply boot the VM off the backup disk, show the auditor that it is running, and the audit is complete through a "verified" or "sure backup".
Since VMs are sitting in the backup system, you can also boot the VM, apply a patch, and perform tests in a "virtual lab" before rolling it out in the primary virtualized environment to minimize risk.
The critical role VMs play in a DR-plagued landscape:
Backing up VMs changes how you recover, how you pass internal audits, and how you test outside of the production environment. Changing backing up just the data to backing up the entire VM also changes your backup infrastructure and process. With the need to boot VMs for instant recoveries, boot VMs for auditors, boot VMs to test software changes and updates outside of production, and the need to perform weekly synthetic fulls, disk is required in the virtualized backup world as you cannot boot from tape and you cannot easily read/write with tape.
For disaster recovery instead of building servers, loading system/application and then recovering the data all you have to do is simply boot the VM as the VM has everything needed, including data, to make the replacement systems production-ready.
In virtualized environments, the changed storage blocks are tracked by the hypervisor via changed block tracking (CBT). The backup application picks up the changed blocks and copies them to the backup storage target. Unlike traditional physical server backup where a full backup is performed every Friday night, in the virtualized world each backup is the changed blocks only. There are backup window benefits to only backing up changed blocks but there is also risk to keeping only changed block backups. If you retain too many CBT backups, the time to restore is painful. In addition, if a block is damaged or corrupted anywhere in the chain, reconstituting a full backup will fail. To overcome this, IT must create a full backup, sometimes called a "synthetic full" backup, at least once a week.
With the need to boot VMs for instant recoveries, boot VMs for auditors, boot VMs to test software changes and updates outside of production, and the need to perform weekly synthetic fulls, disk is required in the virtualized backup world as you cannot boot from tape and you cannot easily read/write with tape.
With CBT, most VM backup applications with a weekly synthetic full will see a storage reduction of 2:1 to as much as 6:1. As the retention period grows, so does the disk storage. With retention periods of four to six copies or greater, the amount of disk storage required becomes quite costly very quickly. Therefore, for four to six copies of retention or less, straight disk can be used. With a larger number of copies, disk-based backup appliances with data deduplication are required. Data deduplication appliances can raise the rate of deduplication in a virtualized environment to as much as 20:1. As a result, far less disk is used, and the cost to store a larger number of copies for retention is far less using dedicated appliances with data deduplication versus using straight disk.
Using a disk appliance with data deduplication requires a high-speed disk cache in order to store full version VMs in order to be able to boot for many scenarios or to be able to easily perform a synthetic full backup. There are two types of disk-based backup appliances.
- The first deduplicates the data inline, which means deduplication occurs on the way to disk and therefore only stores deduplicated data. In order to be able to boot a VM, you need to put a straight disk storage cache in front of the appliance in order to have full VMs ready to boot and then have the longer-term deduplicated storage in the appliance.
- The second type of appliance has both built in to a single integrated appliance. These appliances have a disk cache or "landing zone" in order to maintain the most recent VMs in their full form ready to be booted or restored and then store all the deduplicated data behind that.
Over the years, backup has changed from backing up data to backing up complete virtualized machines with a critical acknowledgment of how DR affects it data center infrastructure. All in all, the move from physical servers to virtualized environments is changing how you prepare, set up, and store backups.
Why not find out more by visiting ExaGrid at IP EXPO Europe 2014 on STAND E18 or joining one of ExaGrid's seminar sessions, and see Andy Palmer, VP of International Sales and Graham Woods, VP of International Systems Engineering explain the importance of the right backup architecture to achieving stress-free backup and recovery, and how a scale-out GRID architecture with landing zone can solve your biggest backup challenges.
Bill Andrews is CEO at ExaGrid
ExaGrid will be exhibiting at IP EXPO Europe on 8-9 October 2014, STAND E18, Excel, London E16 1XL.
Seminar sessions:
Wednesday 08th October, 14:20 -- 14:50
Theatre: Enterprise Storage & Data Management
Thursday 09th October, 15:00 -- 15:30
Theatre: Backup & Recovery
Register for IP EXPO now!
Published under license from ITProPortal.com, a Net Communities Ltd Publication. All rights reserved.






 Google seems like it just doesn’t care about these seemingly little things. For example the bazillion emoticons Google paraded so proudly aren't even bug free; the recent tab doesn't remember the ones I use most, doesn't sync across devices, and is sometimes just blank. Oh, and the new emoticons are obviously not present in the weird chat dialog that accompanies Hangout video calls.
Google seems like it just doesn’t care about these seemingly little things. For example the bazillion emoticons Google paraded so proudly aren't even bug free; the recent tab doesn't remember the ones I use most, doesn't sync across devices, and is sometimes just blank. Oh, and the new emoticons are obviously not present in the weird chat dialog that accompanies Hangout video calls.

 Russel Cooke is a business consultant specializing in Customer Relationship Management. In his free time, he contributes predominantly business-related articles, something he enjoys doing tremendously. You can follow Russel on Twitter
Russel Cooke is a business consultant specializing in Customer Relationship Management. In his free time, he contributes predominantly business-related articles, something he enjoys doing tremendously. You can follow Russel on Twitter 
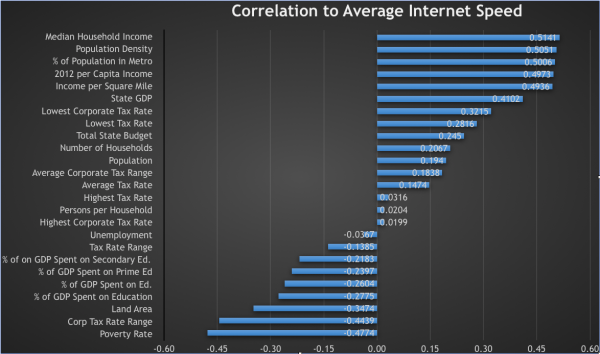
 John continually offers unique insights and a fresh point of view. Along with writing, John has a passion for music. He is the lead vocalist and secondary guitarist for The Family Gallows in Salt Lake City.
John continually offers unique insights and a fresh point of view. Along with writing, John has a passion for music. He is the lead vocalist and secondary guitarist for The Family Gallows in Salt Lake City.















{kind=link}