


Sponsorisé par Orixa Media.
Vous avez un site web et vous vous demandez si vous devriez gérer le SEO vous-même ou confier cette mission à des pros ? Il n’y a pas de réponse toute faite ! Mais pas de panique, on vous a concocté une checklist pour vous aider à y voir plus clair. Vous allez pouvoir évaluer votre situation, vos besoins et décider sereinement de ce qui est le mieux pour votre site. Alors, prêt à faire le point ?
13 questions pour savoir si vous devez travailler avec une agence SEO :1. Avez-vous des collaborateurs capables de gérer une campagne de SEO de A à Z ?
 Oui : Formez vos collaborateurs sur des compétences additionnelles et équipez-les avec les bons outils pour structurer vos efforts en interne.
Oui : Formez vos collaborateurs sur des compétences additionnelles et équipez-les avec les bons outils pour structurer vos efforts en interne.
 Non : Faites appel à une agence SEO, une solution pour vous permettre d’avancer sur ce sujet au plus tôt, de la stratégie à la mise en application.
Non : Faites appel à une agence SEO, une solution pour vous permettre d’avancer sur ce sujet au plus tôt, de la stratégie à la mise en application.
2. Le SEO est-il une priorité dans leur planning ?
Oui : Allouez-leur du temps et établissez une stratégie claire pour avancer efficacement. Une méthode comme les OKR peut permettre à vos équipes de gagner en productivité et en efficacité sur la mise en place des projets SEO internes.
Non : Déléguez tout ou partie des missions à une agence, ou revoyez vos priorités si le SEO n’est finalement pas si important dans votre stratégie digitale.
3. Êtes-vous en mesure de corriger les erreurs techniques ?
Oui : Passez à l’action en réalisant un audit interne pour identifier et corriger les éléments qui bloquent votre référencement.
Non : Faites appel à une agence SEO qui effectuera un audit de votre site, vous proposera des recommandations concrètes et qui pourra même intégrer des optimisations directement sur votre site (correctifs techniques, ajout de contenu, optimisation SEO, achat de backlinks…)
4. Pouvez-vous produire du contenu optimisé pour le SEO ?
Oui : Concentrez-vous sur la recherche de mots-clés pertinents, vérifiez si les intentions de recherche correspondent à vos templates et définissez une stratégie éditoriale sur plusieurs mois.
Non : Externalisez la création de contenu à des experts. Une agence spécialisée en création de contenus SEO pourra définir une stratégie éditoriale, une roadmap et vous accompagner dans la mise en application du plan d’action.
5. Êtes-vous en capacité de mettre en œuvre une stratégie de netlinking efficace ?
Oui : Lancez des campagnes ciblées pour obtenir des backlinks de qualité. Travaillez avec vos partenaires, la presse spécialisée et/ou local et dénichez des liens puissants et de confiance vis-à-vis de Google.
Non : Confiez cette tâche à un expert du netlinking. Une agence de netlinking aura en charge la définition de la stratégie de linkbuilding et pourra acheter ou créer des liens vers votre domaine et les pages à booster.
6. Avez-vous besoin d’un audit pour établir une roadmap ?
Oui : Faites appel à une agence SEO pour réaliser un audit complet qui guidera vos actions sur les mois à venir. L’audit va faire un point sur les forces et les faiblesses de votre site en termes de référencement naturel, pour définir les facteurs bloquants et les corrections à apporter par ordre de priorité.
Non : Si vous avez déjà réalisé un audit SEO, utilisez-le pour définir vos priorités des mois à venir et planifier vos actions.
7. Avez-vous identifié vos objectifs SEO ?
Oui : Alignez vos actions sur ces objectifs. Assurez-vous que vos outils de tracking sont bien paramétrés pour mesurez régulièrement vos progrès et la réussite de vos actions.
Non : Prenez le temps de définir des objectifs ou faites-vous accompagner pour les choisir en fonction de vos priorités business. C’est la phase la plus importante de tout projet SEO (et plus globalement, de tous les projets digitaux).
8. Avez-vous besoin d’un regard extérieur pour valider ou sécuriser vos projets SEO ?
Oui : Une agence peut vous apporter une double validation et un point de vue neutre pour éviter les angles morts.
Non : Vraiment pas ? Même pas un coup d'œil ? Bon… Si vous êtes sûr de vos choix 
9. Le SEO est-il une priorité immédiate pour votre entreprise ?
Oui : Déployez rapidement des actions concrètes avec une agence pour ne pas perdre de temps et obtenir des résultats au plus tôt.
Non : Prenez le temps d’évaluer vos besoins et préparez une stratégie SEO adaptée à vos objectifs futurs, en interne ou avec l’aide d’une agence SEO dans le futur.
10. Avez-vous des problématiques techniques avancées ? (exemples : problématiques SEO local, Shopify, Javascript…)
Oui : Faites auditer votre site par des spécialistes de ces problématiques pour identifier et résoudre ces points bloquants.
Non : Vous pouvez vous concentrer sur les fondamentaux avec des ressources internes, ou vous former sur les sujets nécessaires pour votre activité.
11. Nécessitez-vous l’intervention d’experts pour des optimisations spécifiques ?
Oui : Par exemple, vous êtes bloqué sur une requête concurrentielle ? Faites appel à un spécialiste pour vous aider sur ce point précis.
Non : Effectuez les optimisations en interne ou déléguez certaines tâches spécifiques.
12. Avez-vous les ressources pour embaucher des experts SEO internes ? (En moyenne, un SEO en France coûte 40 000€ brut par an, soit 56 000€ avec charges, selon l’étude emploi Fepsem 2021)
Oui : Investissez dans une équipe dédiée pour internaliser votre stratégie SEO.
Non : Si vous n'avez pas le budget pour recruter, vous pouvez définir un budget qui vous permettra d'externaliser certaines actions SEO (la stratégie, l'acquisition des liens, la création de contenu, etc.)
13. Êtes-vous prêt à investir dans une collaboration avec une agence ?
Oui : Choisissez une agence SEO qui répond à vos besoins, qui vous propose un accompagnement sur mesure, adapté à vos besoins et qui comprend vos enjeux business. Un vrai partenaire avec qui vous pourrez travailler dans la durée !
Non : Explorez des options alternatives moins coûteuses comme la formation ou les outils en ligne pour développer votre stratégie SEO à votre rythme.
Si vous avez plus de 7 , vous avez sûrement besoin de vous faire accompagner par une agence SEO. A minima pour obtenir un point de vue externe et porter un autre regard sur les actions que vous menez actuellement sur votre projet.
"Faire appel à une agence SEO répond souvent à des besoins très spécifiques. Par exemple, beaucoup d’entreprises n’ont pas les compétences internes nécessaires pour bâtir une stratégie SEO efficace et complète. C’est un domaine qui évolue constamment, et sans expertise dédiée, il est difficile de rester performant.
Un autre point clé, c’est le manque de temps. Les équipes en interne sont souvent débordées, et externaliser certaines tâches, comme la gestion du netlinking ou l’optimisation technique, devient indispensable.
Mais ce que j’observe également, c’est l’importance d’avoir un regard externe. Une agence apporte une vision critique, neutre et enrichissante. Cela permet de challenger les idées préconçues et d’affiner les stratégies pour atteindre les objectifs.
Enfin, une agence, c’est aussi un accès à des ressources spécialisées : outils pointus, experts dédiés et analyses régulières pour piloter la performance et ajuster en continu. En résumé, faire appel à une agence SEO, c’est gagner en expertise, en efficacité et en hauteur de vue pour optimiser sa visibilité."

Victor Lerat
DG d'Abondance.com
Pas besoin de devenir expert en SEO, l’agence s’en charge pour vous. Elle réunit des professionnels du contenu, de la technique, du netlinking, de l’UX... Pour un site vitrine ou pour un gros site e-commerce, ils savent exactement quoi faire pour booster vos résultats.
Un vrai gain de tempsLe SEO, c’est chronophage et il faut le travailler en continu. Une agence s’occupe de tout pendant que vous vous concentrez sur ce que vous faites de mieux. Pas besoin de jongler entre vos projets et les audits et autres optimisations !
Des outils de proLes agences ont accès à des outils performants pour analyser votre site, surveiller vos concurrents, ou suivre vos résultats. Vous bénéficiez directement de ces outils sans avoir à payer les abonnements vous-même, et surtout sans avoir besoin d’apprendre vous-même à utiliser ces outils (parfois complexes).
L’article "Dois-je faire appel à une agence SEO : Le quiz pour vous aider !" a été publié sur le site Abondance.

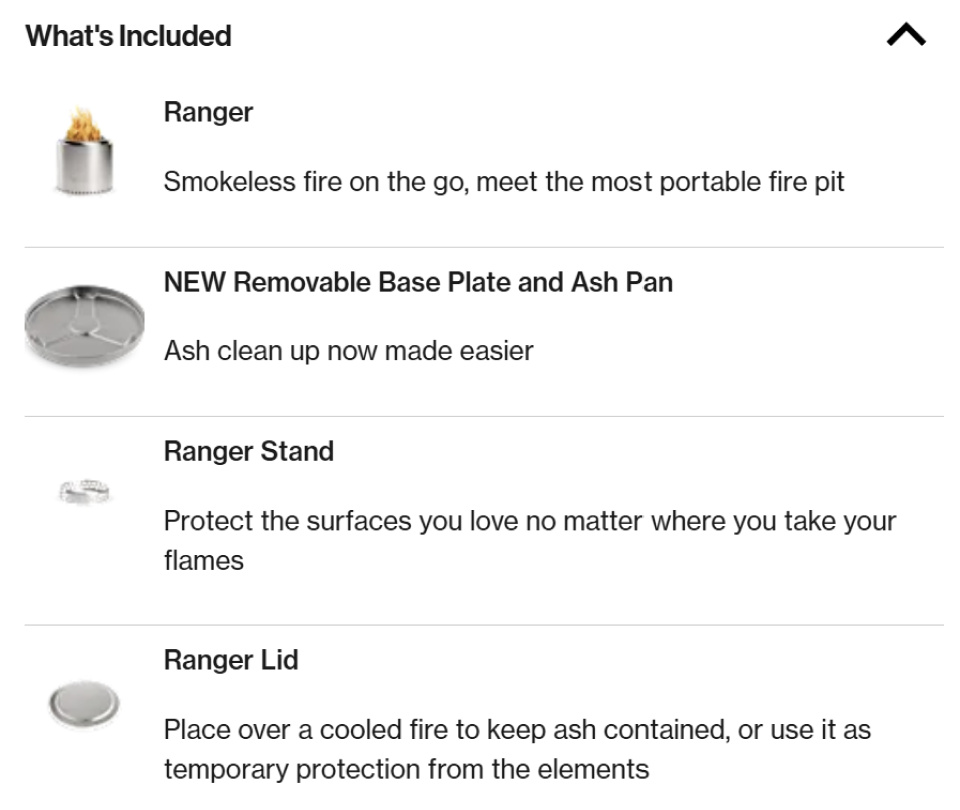
 Titres <hN> uniques et uniquement utilisés pour structurer le contenu
Titres <hN> uniques et uniquement utilisés pour structurer le contenu


 Les basiques sont un acquis pour vous ? Voici des inspirations d'astuces SEO et UX de fiches produits, pour monter d'un niveau dans l'optimisation de la visibilité dans les moteurs de recherche ET de la conversion.
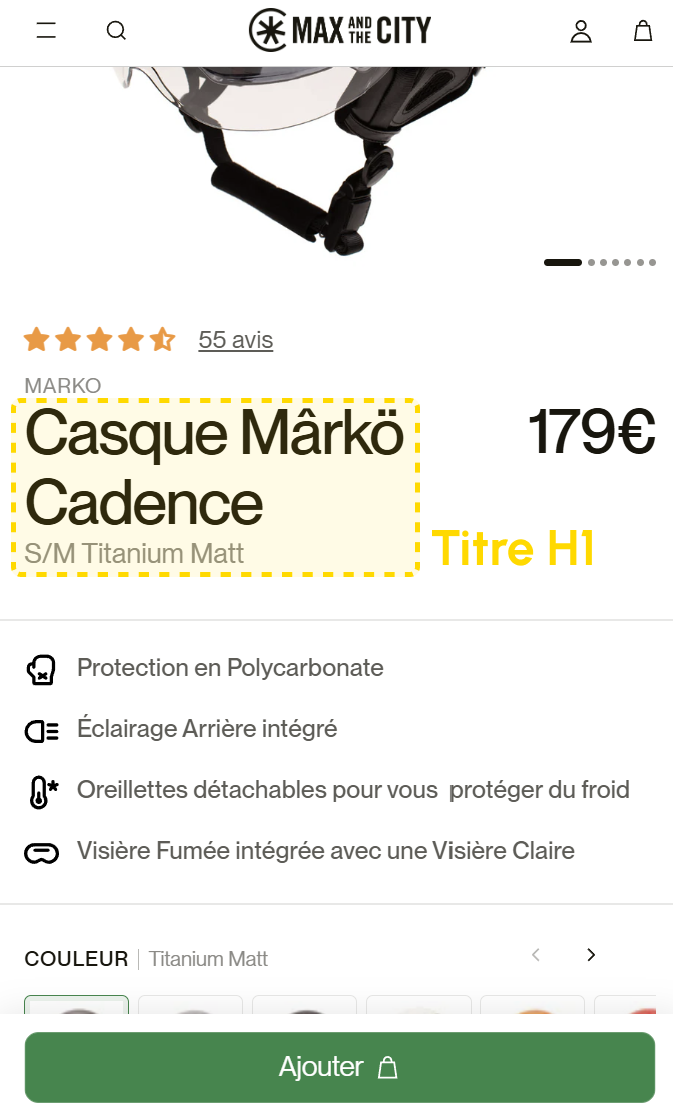
Titres H1 à la fois complets, uniques et user-friendly
Les basiques sont un acquis pour vous ? Voici des inspirations d'astuces SEO et UX de fiches produits, pour monter d'un niveau dans l'optimisation de la visibilité dans les moteurs de recherche ET de la conversion.
Titres H1 à la fois complets, uniques et user-friendly

 Liens internes vers les catégories depuis les attributs des produits
Liens internes vers les catégories depuis les attributs des produits
 Exploiter la puissance des avis utilisateurs sur vos produits
Exploiter la puissance des avis utilisateurs sur vos produits
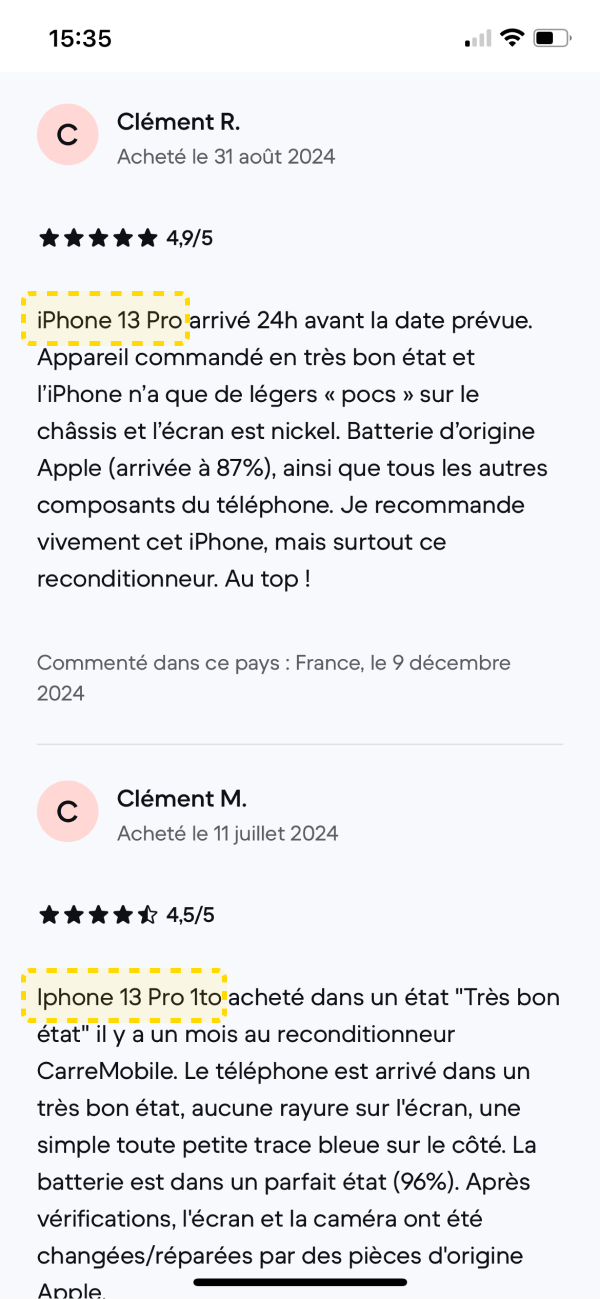 Sur la fiche produit de
Sur la fiche produit de 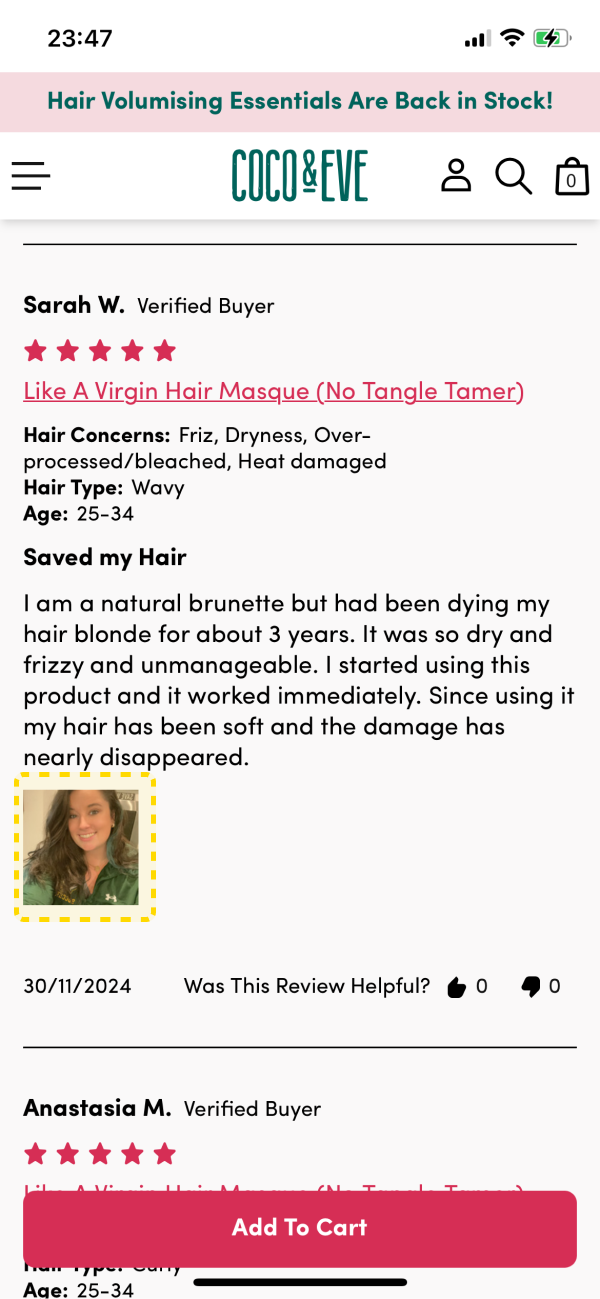 Vous voulez exploiter l'IA pour un usage plus pertinent que des kilomètres de texte ? Alors utilisez-la pour les avis !
Sur ses fiches produit,
Vous voulez exploiter l'IA pour un usage plus pertinent que des kilomètres de texte ? Alors utilisez-la pour les avis !
Sur ses fiches produit, 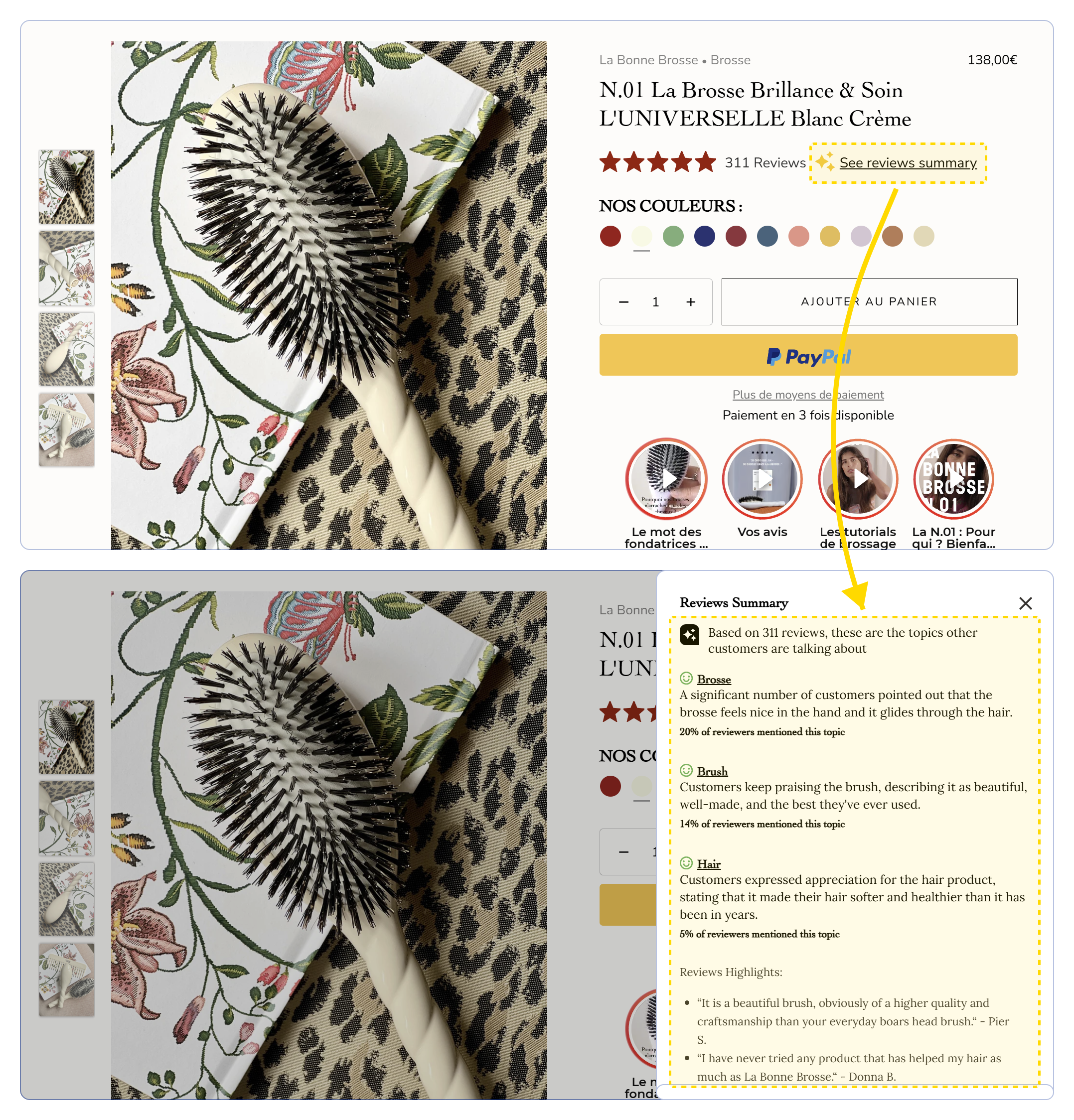 Des images high-level pour optimiser votre SEO sur Google & les autres moteurs visuels
Des images high-level pour optimiser votre SEO sur Google & les autres moteurs visuels

 Sur la fiche produit de
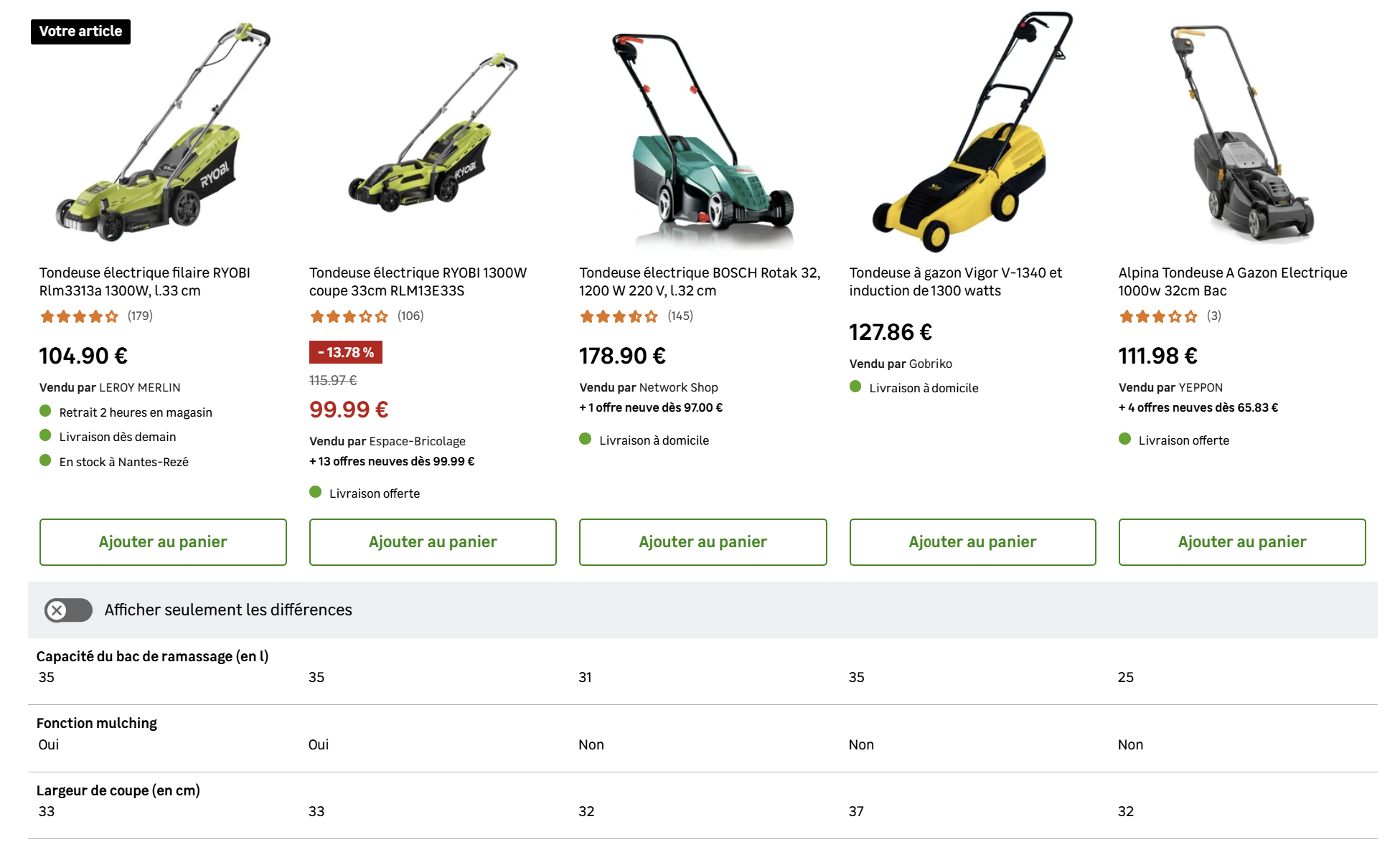
Sur la fiche produit de 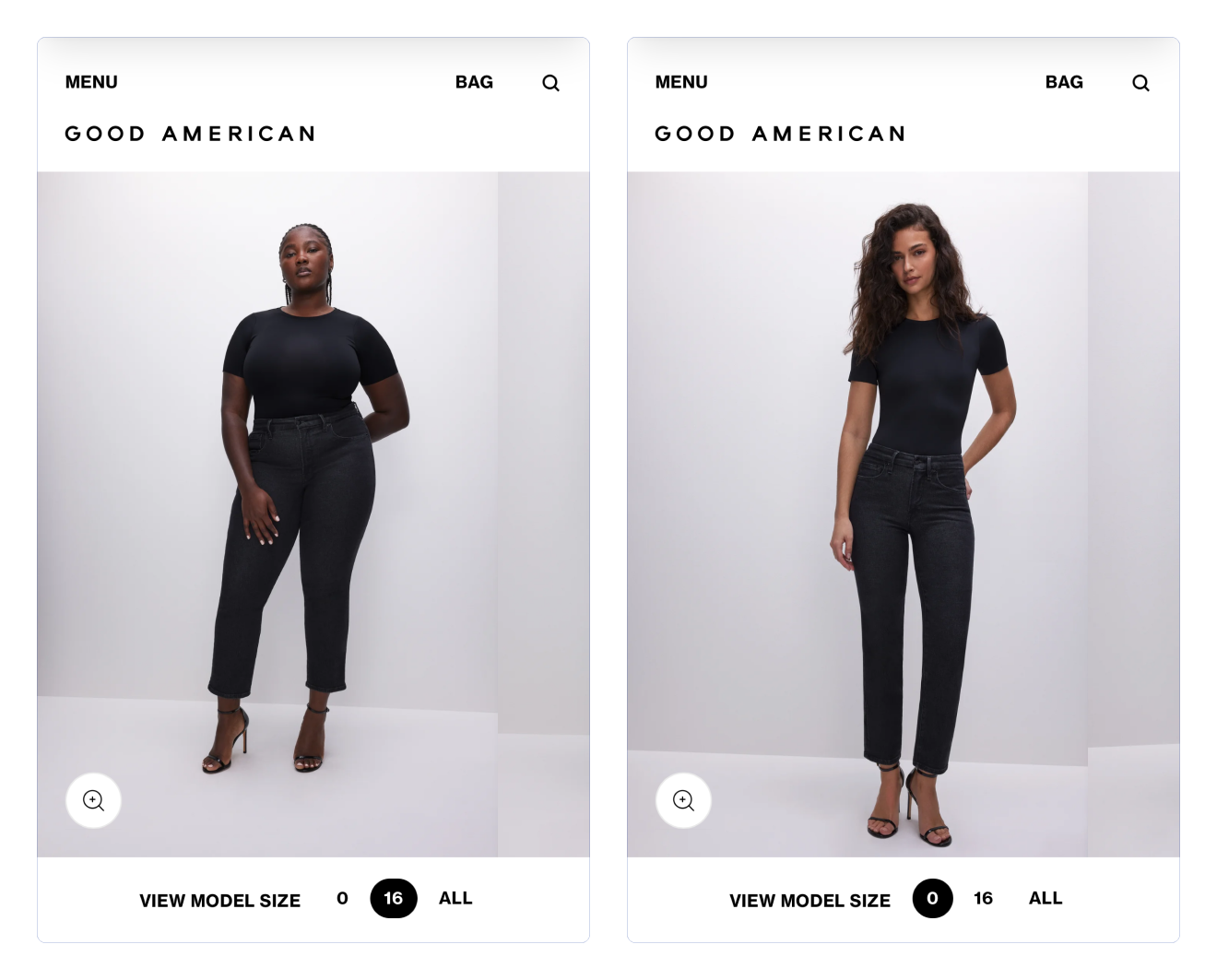 Enrichir sa sémantique par le biais d'un comparateur au sein de la fiche produit
Enrichir sa sémantique par le biais d'un comparateur au sein de la fiche produit
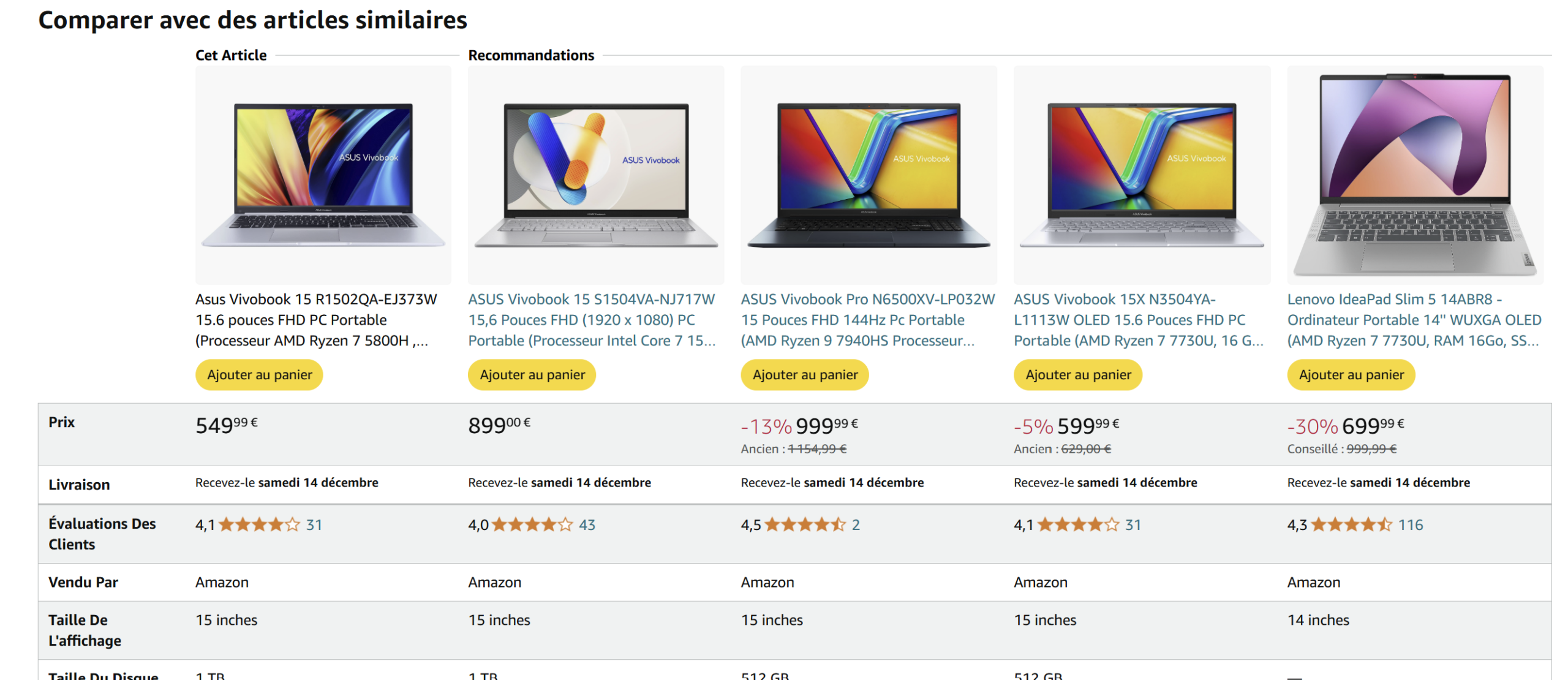
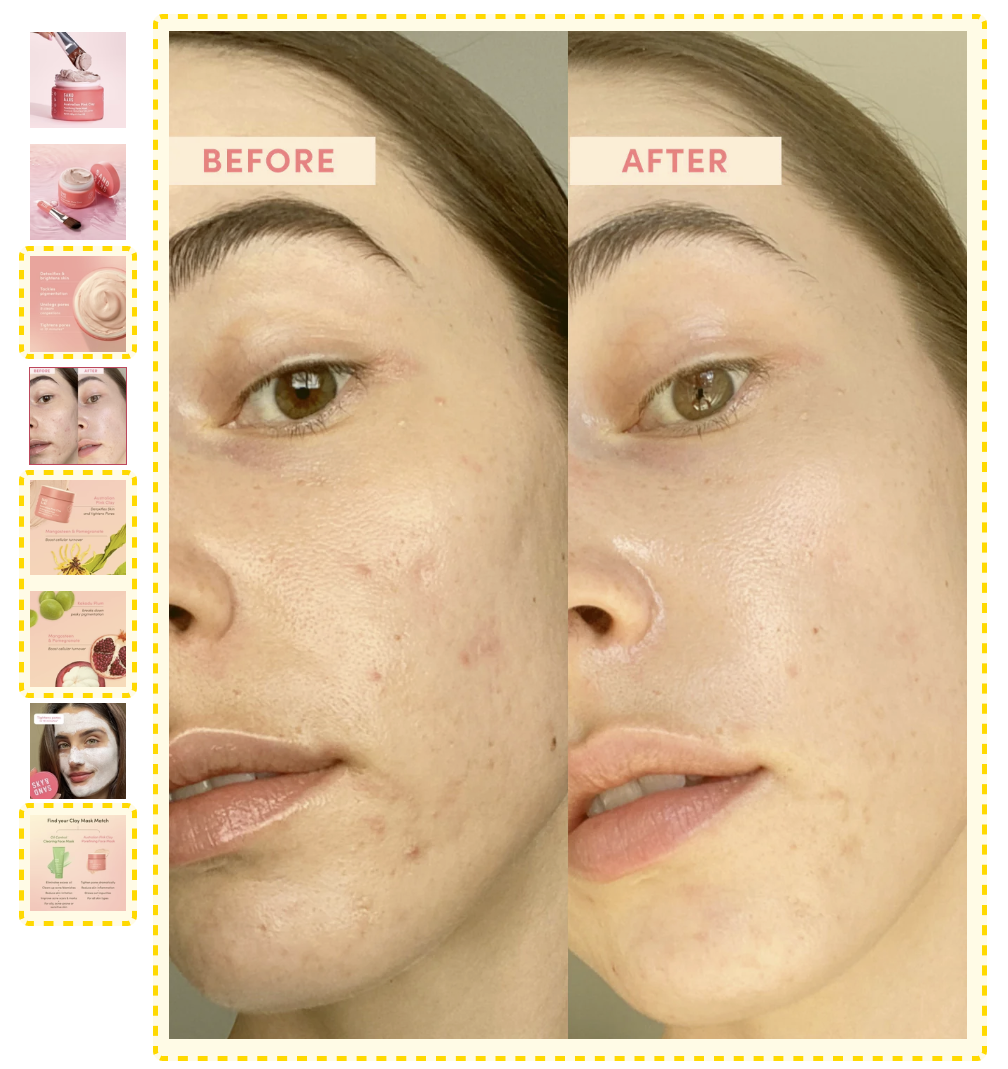
 Expérience sensorielle et visuelle
Expérience sensorielle et visuelle
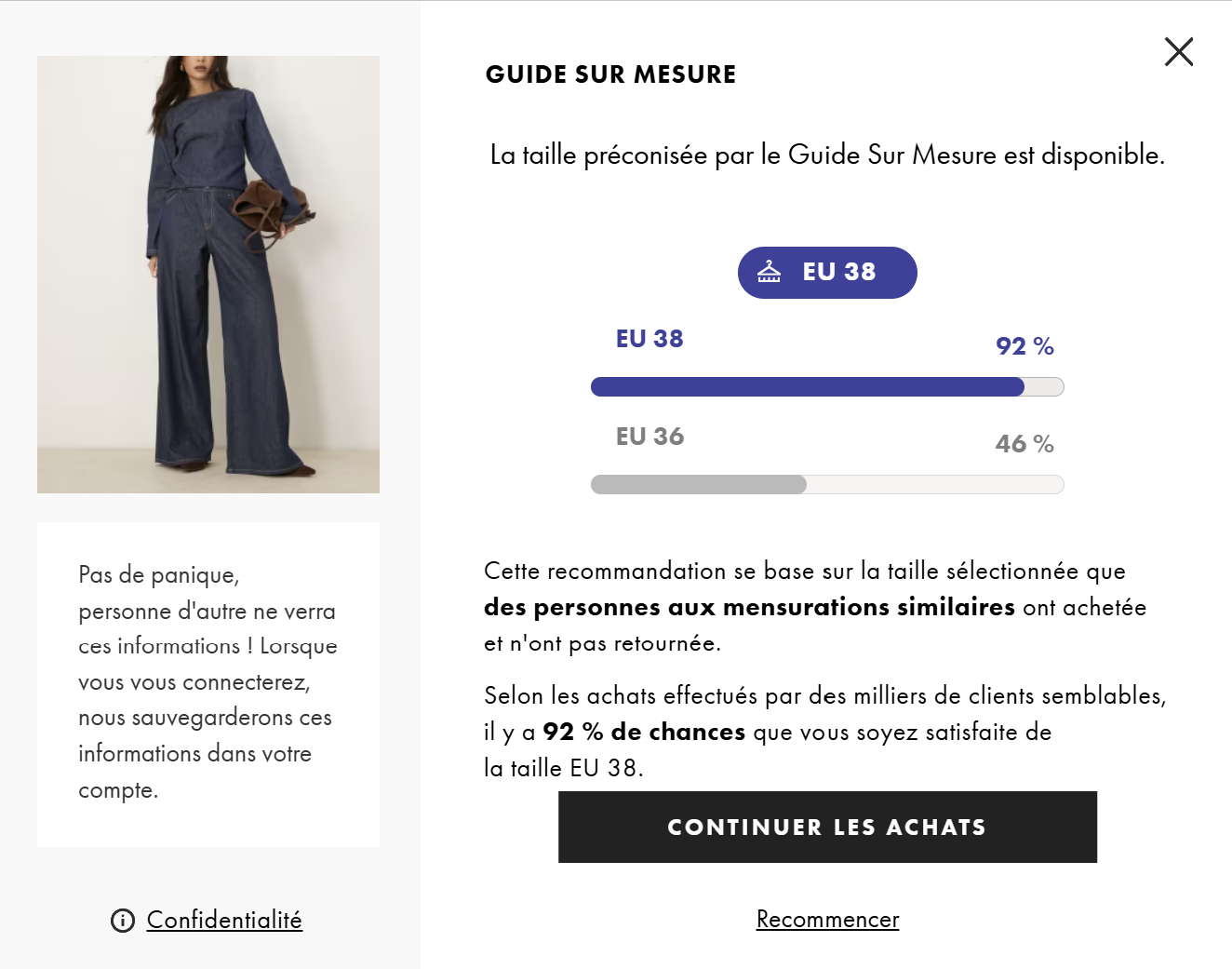
 Guide de tailles sur-mesure
Guide de tailles sur-mesure
 Maintenant que vous avez toutes les clés en main, il est temps de tester par vous-même ! Priorisez, testez, et adaptez vos fiches produits pour maximiser leur potentiel SEO et offrir une expérience utilisateur optimale. Besoin d’un coup de pouce ? Commencez par appliquer une ou deux astuces dès maintenant, et observez les résultats !
Maintenant que vous avez toutes les clés en main, il est temps de tester par vous-même ! Priorisez, testez, et adaptez vos fiches produits pour maximiser leur potentiel SEO et offrir une expérience utilisateur optimale. Besoin d’un coup de pouce ? Commencez par appliquer une ou deux astuces dès maintenant, et observez les résultats !


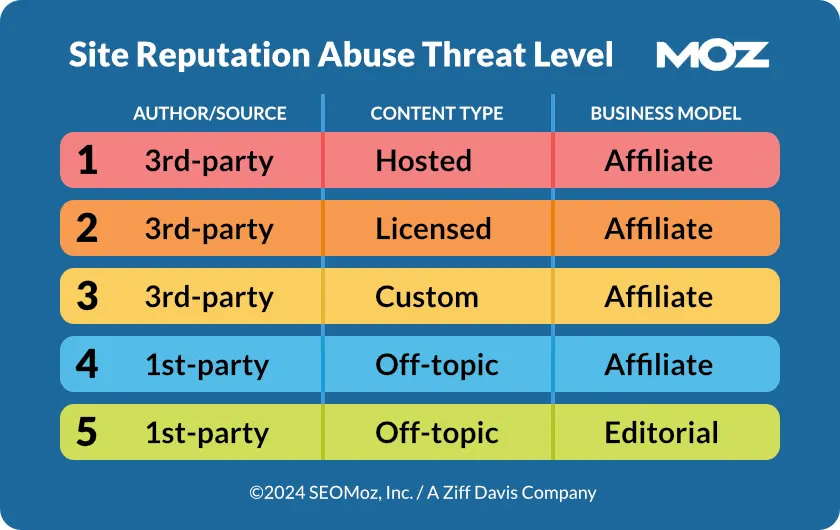 Échelle de risque mise en place par Moz - Source : Moz
Échelle de risque mise en place par Moz - Source : Moz