


PdfTrick is a free open-source tool for selectively extracting images from PDF documents.
Yes: selectively. Unlike most of the competition, PdfTrick doesn’t dump hundreds of files in a folder -- it only saves the images you actually need.
The program requires Java 1.8, but as long as you’ve got that already it’s very convenient to use: simply download, unzip and run the single executable.
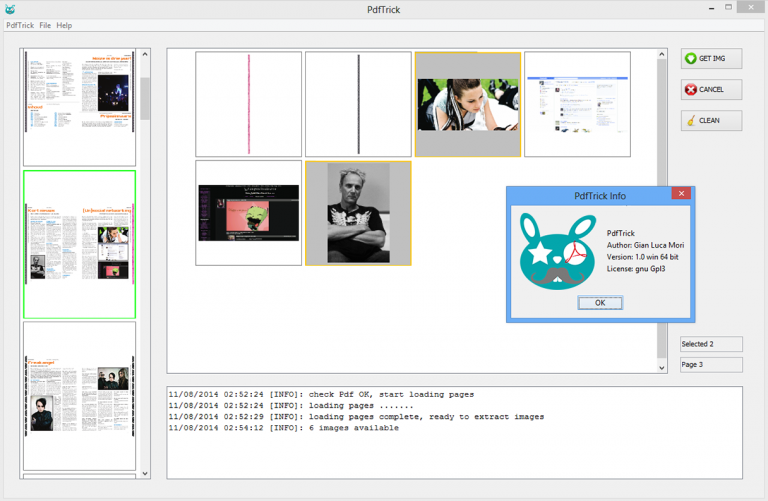
Importing is as easy as dragging and dropping one or more PDFs into the left-hand sidebar. Their page thumbnails are displayed for browsing.
Scroll through the pages, click on anything interesting (a single page only, no multi-selection allowed) and PdfTrick generates thumbnails for every image on that page.
Select one or more of these images, click "GET IMG", choose your destination folder, and the images are extracted and saved to a subfolder with a name based on the date and time (PdfTrick_dd-mm-yyyy_hh.mm.ss\img_1.jpg, PdfTrick_dd-mm-yyyy_hh.mm.ss\img_2.jpg etc).
This isn’t a very helpful naming convention. File names like "img_x.jpg" don’t tell you where they came from, date and time subfolders aren’t exactly informative either. We’d have preferred something based on the PDF document name, along the lines of Name.p5.i3.jpg for image 3 on page 5 of Name.pdf, for example.
Still, if you only need to extract a few images from a PDF then that probably won’t matter very much, and overall PdfTrick’s selective approach to image extraction may save you a little time.
PdfTrick is an open source application for Windows and Mac.