


Extracting text from a PDF can be very easy. Just select a section and copy it to the clipboard, or maybe -- in Adobe Reader -- click File > Save As Other > Text to save the entire document.
This all works just fine, too, until you come across a PDF which is all images. And that’s when you need something a little more powerful.
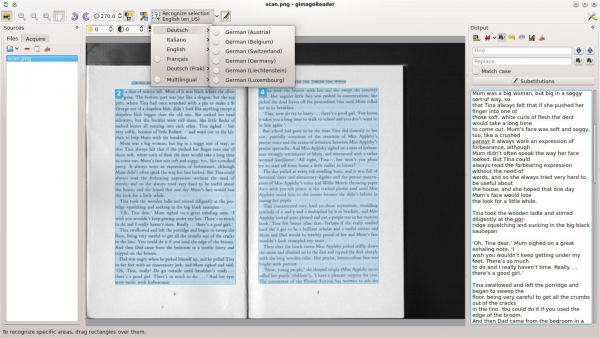
GImageReader is an open source front end for the Tesseract OCR engine, and can extract text from PDFs, image files, or by acquiring them from your scanner. If that's not enough it also accepts images from the clipboard, or by taking a screenshot.
A one-click "Autodetect layout" option will hopefully detect all the text regions within the source. The reliability of this can be anything from "amazing" to "useless", depending on the image, but you can delete or reorder the regions as necessary. Or you might select a block manually by clicking and dragging with the mouse.
If the task is a simple one -- just a paragraph or two of high quality text -- you could just right-click a region and select "Recognize to clipboard". GImageReader grabs whatever text it can from the image and copies it to the clipboard, ready for immediate reuse elsewhere.
Longer blocks can be sent to an "Output" pane for cleaning up. There’s nothing too advanced -- search and replace, stripping line breaks, a chance for manual editing -- but it might be helpful, and when you’re done the results can be saved as a TXT file.
GImageReader’s interface is a little awkward in places, but once you've figured it out it’s easy enough to use, and the Tesseract engine can be very accurate. The program is available now for Windows XP+ and Linux.